Data events recovery
Every data event that the Pismo platform successfully publishes is securely replicated and stored in a dedicated S3 bucket. In situations where your application becomes unable to receive events for a period of time, you can access this resource to recover them.
Can’t Pismo simply redeliver my events?To maintain our commitment to our SLOs (service level objectives) and avoid putting your operations at risk, the Pismo platform does not provide event recovery using the real-time streaming method. By enabling you to recover events directly using the batch upload method, you decide how and when to perform the recovery.
Reprocess events from backup files
PrerequisitesTo perform this activity, make sure that you have properly set up event delivery. In addition, you need:
- AWS account credentials.
- Amazon Resource Names (ARN) of both S3 buckets: Pismo’s (the source) and yours (the destination).
- You also must understand how to assume the Pismo IAM role in AWS.
S3 bucket name
The name of your S3 bucket includes your organization’s ID (also known as the tenant ID). The name is generated according to the following pattern:
s3://pismo-dataplatform-<your_org_id_in_lowercase>
For example:
s3://pismo-dataplatform-tn-34778262-f4f0-464d-b4c6-a14e2dc6f4be
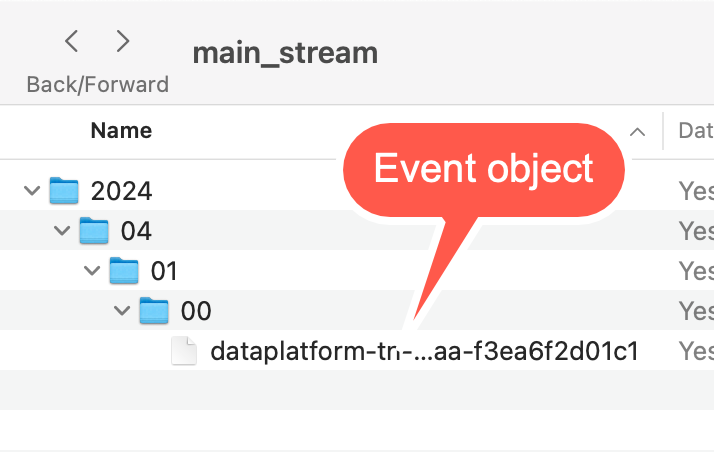
Event object directory structure
Events are stored as text files in JSON format. The JSON data is in its rawest possible form, to avoid any difference with the original event from the real-time topic. Events are written into the text file sequentially and without delimiters between the events. Event data is batched for 5 minutes or until it reaches 10MB in size and then saved as a new object containing event JSON data.
Object names use the following directory structure (which is based on the date and time when the Pismo platform published the event to its subscribers):
/main_stream/<year>/<month>/<day>/<hour>/
| Element | Description |
|---|---|
| main_stream | Internal application name (this never changes) |
| year | YYYY |
| month | MM |
| day | DD |
| hour | HH |
Event object name
The object name is generated according to the following pattern:
dataplatform-<your_org_id>-<sequential_file_number>-<year>-<month>-<day>-<hour>-<minute>-<second>-<file_hash>
For example:
dataplatform-tn-34778262-f4f0-464d-b4c6-a14e2dc6f4be-5-2024-04-01-00-04-35-1142260c-c088-427a-bbaa-f3ea6f2d01c1
| Element | Description |
|---|---|
| dataplatform | Pismo S3 bucket name (this never changes) |
| your_org_id | Your organization ID |
| sequential_file_number | Sequence number of the generated file (starting from 1) |
| year | YYYY |
| month | MM |
| day | DD |
| hour | HH |
| second | SS |
| file_hash | Unique, fixed-length, and encrypted string of characters that represents the file's contents. |
Application example
This section provides an example Python script for recovering event data. It uses Apache Spark to read the events from a specific period in parallel, as a partitioned table.
DisclaimerThe example below is provided solely as an example to improve understanding — it is not intended to provide a solution, only a starting point for your customization and implementation planning. It is incumbent upon you to adapt it to your actual infrastructure, the technologies you employ, your authentication model, and so forth.
The script reads event data from the Pismo S3 bucket for your organization, processes it using PySpark, and then writes the result to the destination S3 bucket that you maintain. (Whenever you need to process a large number of events, it’s a good idea to use a parallel processing framework like Spark.)
p_org_id = 'tn-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'
p_start_date = 'YYYY-MM-DD'
p_end_date = 'YYYY-MM-DD'
p_dest_bucket_path = 's3://{your_staging_area_bucket}/{your_staging_area_path}/'
# COMMAND ----------
from pyspark.sql.functions import split, explode, expr, regexp_replace, col,from_json
from pyspark.sql.types import StructType, StructField, LongType, StringType, DoubleType
from datetime import datetime, timedelta
from functools import reduce
from pyspark.sql import DataFrame
import concurrent.futures
# COMMAND ----------
def convert_to_date(input_date):
try:
validated_date = datetime.strptime(input_date, '%Y-%m-%d').date()
return validated_date
except:
dbutils.notebook.exit("Invalid Input Date : " + input_date)
# COMMAND ----------
def is_valid_range(start_date, end_date):
start = convert_to_date(start_date)
end = convert_to_date(end_date)
if start > end :
dbutils.notebook.exit("Invalid Date Range... Start Date: " + str(start_date) + " / End Date: " + str(end_date))
# COMMAND ----------
def get_paths(org_id, start_date, end_date):
aux = start_date
paths = \[]
while aux \<= end_date :
year = aux.year
month = aux.month
day = aux.day
source = 's3://pismo-dataplatform-{org_id}/main_stream/{year}/{month}/{day}/_/\_'.format(org_id=org_id, year=year, month=str(month).rjust(2, '0'), day=str(day).rjust(2, '0'))
path = {'date': str(aux), 'path': source}
paths.append(path)
aux = aux + timedelta(days=1)
return paths
# COMMAND ----------
SCHEMA = StructType(
[
StructField('event_id', StringType(), True),
StructField('cid', StringType(), True),
StructField('org_id', StringType(), True),
StructField('event_type', StringType(), True),
StructField('domain', StringType(), True),
StructField('schema_version', LongType(), True),
StructField('arrival_epoch', LongType(), True),
StructField('timestamp', StringType(), True),
StructField('data', StringType(), True)
]
)
is_valid_range(p_start_date, p_end_date)
# COMMAND ----------
START_DATE = convert_to_date(p_start_date)
END_DATE = convert_to_date(p_end_date)
ORG_ID = p_org_id.lower().strip()
EXECUTION_ID = datetime.now().strftime("%Y%m%d-%H%M%S%f")
DEST_BUCKET_PATH = p_dest_bucket_path
# COMMAND ----------
def generate_output_path(date):
output = '{path}/execution_id={execution_id}/org_id={org}/date={date}'.format(path=DEST_BUCKET_PATH.rstrip('/'), org=ORG_ID, execution_id=EXECUTION_ID, date=date)
print("Persisting output path: " + output )
return output
# COMMAND ----------
def read_write_s3_path(source):
path = source['path']
date = source['date']
df = spark.read.text(path)
.withColumn('value', explode(split(regexp_replace(col('value'), r'\}\{', '}\\n{'), '\\n')))
.withColumn('value', from_json(col('value'), SCHEMA)).selectExpr("value.\*")
output_path = generate_output_path(date)
df.repartition(5).write.mode('append').parquet(output_path)
optimized_df = spark.read.parquet(output_path)
return optimized_df
# COMMAND ----------
def read_paths_in_parallel(org_id, start_date, end_date):
s3_paths = get_paths(ORG_ID, START_DATE, END_DATE)
with concurrent.futures.ThreadPoolExecutor() as executor:
dataframes = list(executor.map(read_write_s3_path, s3_paths))
combined_df = reduce(DataFrame.union, dataframes)
return combined_df
# COMMAND ----------
df = read_paths_in_parallel(ORG_ID, START_DATE, END_DATE)
# COMMAND ----------
df.createOrReplaceTempView('read_events')
# COMMAND ----------
query="""
SELECT \*
FROM read_events
WHERE to_date(from_unixtime(arrival_epoch / 1000)) BETWEEN to_date('{START_DATE}') AND to_date('{END_DATE}')
""".format(START_DATE=START_DATE, END_DATE=END_DATE)
print(query)
# COMMAND ----------
df_output = spark.sql(query)
# COMMAND ----------
display(df_output)Updated 4 months ago